
跟着网络存储、云核算、物联网、视频监控等信息技术在人们日常作业、学习、日子中的运用,各类存储介质成为人们日子作业不可或缺的一个部分,海量数据存储在核算机、网络服务器及各种存储介质中,而一旦因各种原因导致数据丢掉、损坏,能否将其恢复就成了是否能够挽回损失的要害。与此一同,相关运用核算机及网络制作、复制传达色情、淫秽物品案子,网上诈骗、敲诈勒索、网络电子传销、运用互联网损害国家安全等案子逐年递加,已折射出我国司法在冲击电子数据违法作业中面对的巨大应战.而冲击电子数据违法的有用办法就是找到具有规律效能的依据,2012年修改经过的《刑事诉讼法》和《民事诉讼法》都已将“电子数据”列为新的一类依据,由此电子数据取证和司法判定在刑事、民事诉逐渐呈现重要作用.核算机上的材料被贪婪主体人为歹意删去,怎样经过找回硬盘数据来取证;硬盘被不尽职主体击打变形,怎样经过提取电子数据证明其不尽职;监控设备“昨日的闯祸逃逸视频”被“今日的常规交通画面”掩盖,什么技术能够将“暂不可见”的“逃逸依据”重见天日.信息时代,电子数据恢复不光运用于人们的日常作业.日子和学习中,还成了公检法部分破案、断案、判案的重要一环,也成为各个行政、执法机关最注重的一种电子数据取证与司法判定技术手法。
1电子数据恢复取证与司法判定现状
现在,我国虽然经过修改《刑事诉讼法》和《民事诉讼法》.现已将“电子数据”列为新的--类依据,但是对电子数据取证的操作规范并没有规律规则,电子数据恢复的技术和服务规范更是缺失,公安部于2009年4月7日发布了《电子证据数据恢复检验技术规范》,而该规范不适用于违法现场勘查,一同该规范也只是简单.地对数据恢复软件的名称进行了认可;最高人民检察院于2009年4月下发了《人民检察院电子依据判定程序规则(试行)》,但该规则没有触及到电子数据恢复及其作业规范在国家规范《信息体系灾害恢复规范》(GB/T209恢复-2007)中也没有触及到电子数据恢复.在学术研讨界,对电子数据恢复取证进行研讨代表性的首要有杜江等I"]研讨的公安部科技计划立异项目:核算机取证中的数据恢复技术研讨,但只针对文件体系分区表为损坏的状况进行数据恢复,也没有详细恢复算法和进程;西安电子科技大学胡跃对依据Windows途径磁盘取证体系数据恢复子体系研讨与结束,但只针对数据恢复取证中的碎片进行剖析,没有将电子数据恢复取证流程规范化,也没有规律监督;我国政法大学沈树强8对电子依据判定视角下的数据恢复问题研讨,但只针对电子数据恢复流程进行了研讨,没有将司法实践中的电子数据恢复技术和作业流程相结合,也没有规律监督.而各规律实务部分和第三方的电子数据司法判定人员一般采用。
FTK,DataRecovery,FinalData等国外数据恢复软件进行电子数据恢复取证和司法判定,而我国对这些数据恢复软件并没有进行资质、合法性及其数据恢复操作规范进行软件测评,各公安、检察机关及第三方的电子数据司法判定人员往往依据职业履历或自行拟定的数据恢复办法进行电子数据取证和司法判定,因此判定定论的规律效能很难得到确保,电子数据作为依据的公正性、权威性.中立性遭到质疑,这必定形成在触及电子数据作为依据的司法实践中影响该类案子的判罚规范,不利于该类案子的审理,乃至不利于。冲击违法、维护受害人.因此,依据国内数据恢复在电子数据取证与司法判定诉讼案子中的运用状况,学习国外数据恢复取证与司法判定的相关规范和程序,树立一致的适应于公检法体系的电子数据恢复取证与司法判定规范与作业流程成为一个亟待解决的问题。
2电子数据恢复取证与司法判定模型
数据恢复分为逻辑类恢复和物理类恢复,物理类数据恢复可经过修理法和替换法结束存储介质的正常辨认,然后进行物理镜像后,便可经过逻辑类恢复数据,因此本文首要对逻辑类数据恢复进行研讨.在数据被删去后,假定没有进行掩盖操作,可运用原有文件特征经过对文件定位结束数据恢复;在已知文件类型的状况下,可运用已树立的文件特征字知识库,经过文件特征字进行相关快速结束数据恢复;关于部分被掩盖的残留数据碎片进行数据剖析、挖掘,运用依据SVM的碎片分类器对碎片进行分类,再用上下文区域碎片重组算法对碎片重组,行进了数据恢复成功率.电子数据恢复取证与司法判定模型将理论和司法实务操作相结.
合,将数据恢复的技术性和电子数据取证与司法判定程序的规律性相结合,然后既行进了数据恢复的功率,也行进了恢复出的电子数据的规律效能。
2.1电子数据恢复取证与司法判定模型
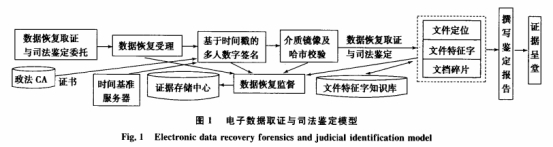
电子数据恢复取证与司法判定模型如图1所示,模型按司法判定实务将电子数据恢复取证与司法判定流程分为数据恢复取证与司法判定托付、判定安排受理、依据时刻戳的多人数字签名、数据恢复介质的镜像与哈希校验、数据恢复取证与司法判定、撰写判定陈述、判定人出庭进行依据呈堂.为确保介质的客观性、原始性、完整性需求有判定托付人、央求人和判定安排等多人进行数字签名,该签名有政法CA发布的证书和依据时刻基准服务器的时刻戳所构成;为了确保原始数据的再现性,行进证明力,数据恢复取证一般都需求对原始介质进行位对位镜像和哈希校验,然后运用镜像进行数据恢复;对电子数据恢复取证与司法判定的全程实施监督,确保数据恢复取证与司法判定出的电子数据在诉讼案子中的可采性力、证明力、规律效能和依据链的完整性.在电子数据恢复操作实务中,依据Windows途径下的FAT和NTFS文件体系,针对文件分区表没有损坏的文件体系,运用文件定位算法快速、精准结束数据恢复取证与司法判定;针对大容量硬盘,运用文件特征字可快速高效地恢复特定类型的文件;针对由于犯人嫌疑人歹意将文件分红碎片躲藏文件及文件分区表损坏的状况,运用依据SVM的碎片分类器对文档碎片进行分类,再运用上下文区域重组算法重组文档碎片.电子数据恢复取证与司法判定操作结束后,需求判定安排人员撰写判定陈述,进行依据呈堂,并在必要时出庭质证。
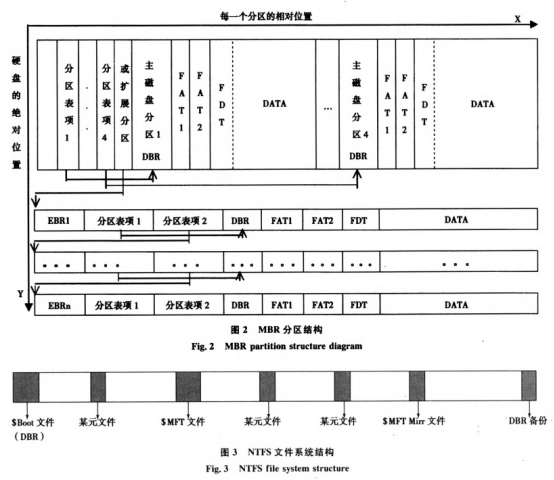
2.2依据文件定位的数据恢复取证与司法判定,MBR(主引导记载)磁盘分区是现在运用最为广泛的一种分区结构、所以论文首要针对MBR磁盘分区进行文件定位数据恢复.在MBR磁盘分区中,分区表占64字节,而每个分区占16字节,故最大可寄存4个主分区,当硬盘的存储容量比较大,而且需求树立更多磁盘分区时,就必须运用扩展分区,用EBR(扩展引导记载)标明,MBR磁盘分区的全体结构见图2所示。
从图2能够看出主磁盘分区经过MBR中分区表进行定位,而扩展分区之间经过指针结构构成一个单向链表结束定位.在FAT16的每个分区表中包含DBR,FAT1/2,FDT和DATA,而FAT32文件体系的FDT
在数据区.NTFS的DBR包含在$BOOT文件中,和文件有关的信息被称为特征,以文件记载的方式寄存在$MFT中,NTFS文件体系方位结构如图3所示。用WinHex:t1] 对MBR磁盘分区常见的文件体系进行剖析,文件的定位算法如下:
1)经过查找MBR/EBR中的分区表信息,获取每个分区的分区类型和该分区的DBR初步扇区数(相对偏移地址一般为63号扇区);
2)读取DBR的BPB(相对偏移地址:0DH ,0EH-0FH,10H,11H-12H和16H-17H)分别获取每簇扇区
数、DBR保存扇区数、FAT个数、根目录项数(-般为512)和每FAT扇区数;IF分区类型为FAT32 ,则读取DBR的BPB相对偏移地址24H-27H获取每FAT扇区数;IF分区类型为NTFS,则读取DBR的BPB相对偏移地址30H-37H获取$MFT初步簇号,跳转到第4步;
3)FDT的初步扇区数= DBR初步扇区数+ DBR保存扇区数+FAT个数*每FAT包含的扇区数,FDT占用扇区数= (根目录项数*32)/ 512.从FDT的初步方位查找已被删去的文件名(第1个字节变为E5),直到找到停止,则该目录项相对偏移地址1AH-1BH,1CH-1FH处的数据即为该文件在DATA区的初步簇号和巨细;IF分区类型为FAT 32,则需求将该目录项相对偏移地址14H-15H(高位)、1AH-1BH(低位)两处的数据兼并作为该文件在DATA区的初步簇号,由于在DATA区中,簇从2初步编号,文件的初步扇区数= FDT的初步扇区数+FDT占用扇区数(文件体系为FAT32时为0)+(初步簇号-2)*每簇扇区数,跳转到第5步;
4)FDT初步扇区数= DBR初步扇区数+ $MFT初步簇号*每簇扇区数+5* 2(5为目录文件的记载
号,2为每个文件记载所占的扇区数),从FDT初步方位运用Unicode编码向下查找已被删去的文件名,直到找到该文件的文件记载(30特征的相对偏移地址42H为该文件名),从80特征的相对偏移地址08H获取常驻特征,IF常驻特征=0,则相对偏移地址10H-13H,14H-15H处的数据即为该文件巨细和初步方位;ELSE相对偏移地址30H-37H,40H处字节的高4位数据即为该文件巨细和DataRun初步簇号,文件的初步扇区数= DBR初步扇区数+ Data Run初步簇号*每簇扇区数;
5)跳转到已删去文件的初步扇区方位,按上步获取的文件巨细,复制该文件内容,按原有文件类型保存为一个新文件,即可结束数据恢复。依据文件定位的数据恢复,可精准恢复被删去的文件,NTFS文件体系中,不论文件是否接连寄存,文件./目录被删去后都可经过该文件记载找到初步簇号进行数据恢复,但当要删去的文件比较多时,需求逐一恢复,作业功率比较低。
2.3依据文件特征字的数据恢复取证与司法判定
一般要恢复的电子数据都是特定的文件格局,比方*.doc.*.xls.*.jpg.*.mpg等格局,而在司惩罚
案中往往要处理许多硬盘.而且容量比较大,因此为行进作业功率,可依据文件首、尾部特征扫描文件体系的数据区,然后供认文件的初步和结束方位.优先快速恢复所需求的特定文件.文献[5]运用word文件的头部和尾部特征结束对* . doc文件的数据恢复.用WinHex抓取的* .jpgl°]文件的首尾特征字如图4、图5所示,从图中能够看出* . jpg文件的头部特征字为0x FFD8FFE000104A464946 ,尾部特征字为0xFFD90000。参照上述办法可求得其他类型文件的首、尾特征字,然后树立依据文件首、尾特征字的文件特征数据库,结束依据文件特征字的数据恢复取证与司法判定,文件特征数据库表见表1所示,缺省巨细为一1时标明没有缺省巨细,方位为0标明从初步向后查找,为一1标明从文件终究向前查找.当文件不接连存储时,在NTFS文件体系中需求凭仗文件记载获取文件存储后续数据块,结束特定文件的数据恢复。
2.4依据文档碎片重组的数据恢复取证与司法判定
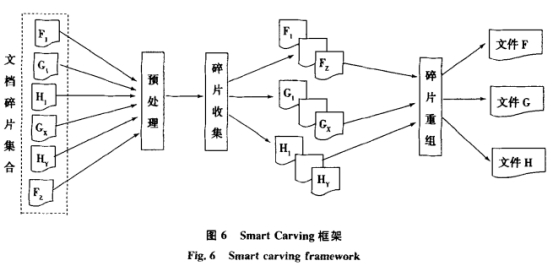
在电子数据取证与司法判定中,由于违法当事人删去、格局化、文件穿插掩盖等人为损坏,构成文档碎片,导致许多存于文件体系元信息无法描绘的未分配区域的电子数据无法被提取,特别是当文件头被掩盖的状况下,依据文件特征的数据恢复将无法正确地进行数据恢复. Metz等针对文档随机碎片问题,提出了SmartCarving结构图,见图6所示.
该结构将文档碎片恢复分为预处理、碎片收集和碎片重组3个阶段,预处理阶段首要处理被紧缩或被加密的数据,清扫已有文件占用的簇;碎片收集首要用于对数据块碎片进行分类;碎片重组是依据碎片分类的作用,重组碎片成文件.为行进文档数据块分类的正确率,有用进行文档重组,然后行进数据恢复的成功率,本文在SmartCarving结构模型的基础上,对碎片收会集文档分类和碎片重组进行了研讨,提出了依据SVM的碎片分类器。
2.4.1 依据SVM的碎片分类器
在碎片收集阶段首要是对许多碎片进行文件分类,现在对碎片进行分类首要有依据间隔的分类和依据机器学习的分类.依据间隔的分类首要是运用不同的文件类型.其字节频率分布度(filefingerprints)不同和接连性字节差异性的特性进行文件分类,这种办法需求对每一个文件类型都树立依据字节频率核算的文件指纹模型,然后设定阀值,假定某个文件数据块与某一个模型的间隔低于设定的阀值,则判定为对应的文件类型,但该办法中很难供认一个比较志向的阀值,另外关于那些字节频率比较类似的文件也很难正确辨认.依据机器学习的分类首要是在核算的基础上树立机器学习模型对文件数据块进行分类,现在最具有泛化才能和最小容错率的支撑向量机( supported vector machines,SVM)分类算法的研讨广受注重,运用与碎片分类描绘如下,本文首先运用Pearson相关系数对包含有Office系列文件.JPEG、C++源码等文件的DFRWS 2007碎片映像数据衡量碎片之间的相关性,练习SVM模型,公式如下:
mn是练习会集的碎片个数,R(i)是第i个文件特征字与已知对应文件类标(类型规范值)的相关性,X...是第k个碎片的第i个特征字,X是第i个特征字的平均值,Y,,Y分别为第k个碎片的类标值和整个碎片的类标值.文件特征字包含以下几个。
1)文件首尾部特征字;2)针对一般文本和图片的信息熵;3)字节/字符频率分布特征,即文件中每个字节/字符的取值规模的核算特征;4)上下文接连字节改动度,即数据块中接连字节之间的平均接连性核算特征由公式(1)知,|R(i)|的改动在0和1之间,值越大,外表该特征关于分类的奉献就越大.依据相关衡量,运用SVM-SFS[9]办法核算每个特征字的权重,然后针对各个文件类型树立依据SVM的多特征字分类器。
2.4.2
碎片重组
文档碎片重组就是对同-一类型的碎片供认联接次序,然后组合成多个不同的文件.运用文件首部特征字和文件摘要信息(文件长度、时刻等文件特征信息)能够供认文件头碎片.而新式文件体系的特征是尽量减少碎片,因此同一个文件的碎片多以2分存在,分红3,4个乃至多个碎片的状况很少见,而且在2分的状况下一般都是从一块接连的区域向邻近的区域空间扩展存储.为此,本文提出了一个上下文区域碎片重组算法如下:
1)供认某个文件头碎片所在区域的地址;
2)运用依据SVM的碎片分类器从该区域初步地址初步次序向后(前)查找,至到不属于该文件类型的碎片,则上述碎片在存储介质上的逻辑寄存次序即为碎片重组的次序;
3)跳过不属于该文件类型的碎片,依据文件碎片头部中的文件巨细,然后运用碎片分类器次序起浮跳动向后(前)查找相同类型文件的数据碎片区域,而且该区域的巨细应该等于该文件剩余巨细;
4)假定第2片区域巨细小于该文件剩余巨细,则有可能是碎片被分红2片以上,则重复进程3),至到查找到该文件全部碎片至,当呈现巨细相同的不同碎片区域或没有找到剩余巨细的碎片区域时,可运用时刻相同或附近的文件特性进行碎片相关和重组。
3试验及作用剖析
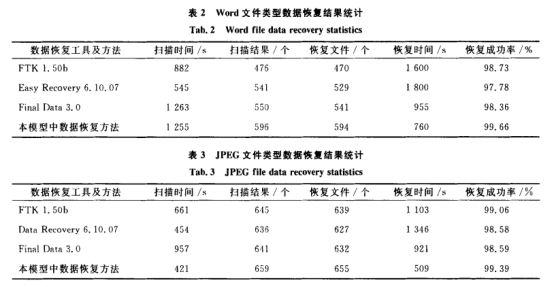
为了验证电子数据恢复取证与司法判定模型的作业功率,选用DFRWS2007发布的数据映像作为试验数据,巨细为256M,该数据映像首要包含OfficeWord,Excel,PDF,BMP,JPEG等文件类型.运用Winhex供给的脚本开发技术和API函数[10]将模型中的算法运用于Winhex中进行原型结束,然后运用电子数据取证.与司法判定中常用数据恢复软件FTK 1. 50b, Data Recovery6. 10. 07 ,Final Data 3.0对该数据映像进行数据恢复剖析比较。试验环境: Intel(R)Core(TM)酷睿i5 M520@2. 40GHz双核,内存2 G,硬盘250 G, Windows 7 Professional.依据文件类型呈现的概率,试验中从文档和图片两大类文件类型中分别挑选了Word和JPEG文件类型进行数据恢复和剖析,作用如表2,3所示。
从表2,3能够看出,关于Word,JPEG文件来说,电子数据恢复取证与司法判定模型中用到的文件定位、文件特征字和文档碎片恢复归纳办法,不论在扫描、恢复时刻上仍是在恢复成功率上都比一般通用数据恢复软件的功率要高.就数据恢复成功率上差不太多,但是在时刻上则大大节省了时刻,这在政法机关进行许多数据文档恢复时特别如此。
定论
本文在对电子数据恢复取证与司法判定现状进行剖析的基础上,提出一种电子数据恢复取证与司法判定模型,该模型按电子数据司法判定实务将电子数据恢复取证与司法判定流程化和规范化,运用多人数字签名、原始介质位对位镜像和哈希校验来行进电子数据的证明力;经过对电子数据取证与司法判定全程进行流程监管与操作监督,确保恢复的电子数据在诉讼案子中的可采性力、证明力、规律效能和依据链的完整性。模型在数据恢复实践中,依据当时Windows途径首要运用的FAT和NTFS文件体系,针对文件体系分区表未损坏的状况,提出了文件定位算法快速恢复;针对规律实务中需求恢复的特定文件类型,提出了文件特征字算法进行数据精准、高效恢复;而关于实践中难于恢复的数据碎片,运用依据SVM的碎片分类器对碎片进行分类,再用上下文区域碎片重组算法对碎片重组,行进了数据恢复成功率.试验作用标明,该模型中所用到的数据恢复算法能够针对实践中不同的状况下进行有针对性数据恢复,特别是司法实践中遇到许多文件需求恢复时将大大节省时刻,行进作业功率,这在规律实务中很可能会有很大协助。
下一步作业将要害研讨其他文件体系,比方针对大容量U盘的ExFAT文件体系、Linux的Ext文件体系(包含Android手机的YAFFS文件体系)、苹果机的HFS+文件体系(包含移动终端文件体系I0S);还包含其他类型文件的特征字,丰富文件类型特征字知识库;并进一步寻找更有用的碎片分类挖掘及相关重组算法。

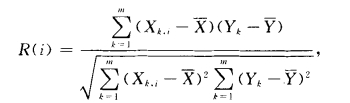
 关注神州,了解更多
关注神州,了解更多